Как Яндекс.Почта стала понимать, что вам нужно

Несколько минут назад Яндекс.Почта анонсировала новый подход к чтению и написанию писем. Мы считаем, что современная почта должна быть намного умнее, чем сейчас. Она должна понимать написанное и сразу помогать отреагировать на него. А также лучше позволять своим пользователям делать что-то совместно. Чуть подробнее о новых возможностях можно почитать в пресс-релизе. В этом посте мы хотим рассказать, как работает одно из самых важных нововведений, объявленных сегодня.
Что именно сделано
Что если почта начнёт делать за вас рутинную работу, связанную с содержанием письма? Например, поможет не забыть о важном мероприятии, напомнит о предстоящем вылете к морю, даст нужные ссылки и полезную информацию. Мы с коллегами из отдела лингвистики применили совершенно особенную технологию, которая, как мы надеемся, изменит представление о том, что такое электронная почта.
Эта технология позволяет автоматически применить к содержимому письма специальные алгоритмы и выделить из него определенные факты в виде понятной компьютеру структуры. Благодаря ей Яндекс.Почта теперь может сообщить вам больше контекстной информации, связанной с вашим письмом.
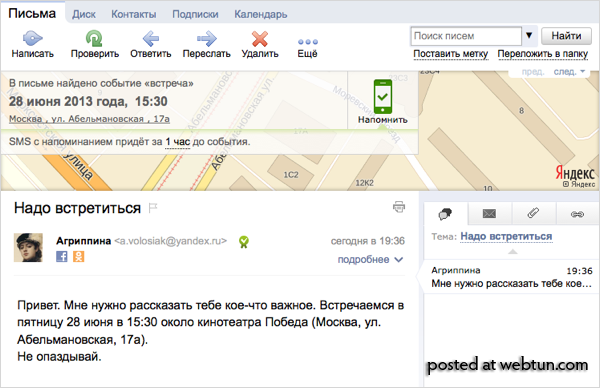
Например, если в письме есть приглашения на какое-либо событие и указано, где именно оно состоится, мы покажем это место на карте и поможем не заблудиться.
Какие технологии стоят за кулисами
Итак, вы получили письмо от друга, где он зовет вас на интересную конференцию или в кино. С точки зрения компьютера, этот текст не более чем набор байтов. Но человек может выделить в тексте ключевые объекты и образы.
Обработка письма в Яндекс.Почте начинается еще в момент его получения и сохранения (мы этот процесс называем «покладка»). Спамооборона при проверке использует эвристические алгоритмы и определяет, к какому типу оно может относиться: электронный билет на самолет, письмо от социальной сети, письмо от человека или т.д.
В зависимости от того, к какому типу будет отнесено письмо, его текст в момент просмотра — в терминах извлечения фактов он называется документом, — отправляется на извлечение в тот или иной обработчик. Обработчики фактов бывают как простыми и быстрыми (например, простые регулярные выражения), так и довольно сложными.
Множество методов, позволяющих машине понимать текст на естественном языке, и реализующих эту возможность алгоритмов, являются частью более общей задачи извлечения информации. Яндекс.Почта извлекает приглашения на события с помощью парсера Tomita, в основе которого лежит алгоритм Масару Томиты. Доступ к нему был открыт в конце 2012 года.
Сам по себе парсер Томита — это инструмент для написания контекстно-свободных грамматик. С его помощью любой человек может описать набор шаблонов, по которым будет структурироваться текст. Парсер работает на основе словарей ключевых слов и правил, которые пишут лингвисты. Словари при этом могут быть довольно большими.
Как распознаются события в письме
Рассмотрим работу парсера на примере. Вы получаете письмо, содержащее следующий текст:
«21 ноября 2013 года в Институте лингвистических исследований РАН (Санкт-Петербург) пройдёт Десятая Конференция по типологии и грамматике для молодых исследователей».
В Томите есть данные о том, какие слова могут быть «вершинами» приглашения. Например глаголы «приглашать», «проходить», «состояться» — здесь есть форма глагола «пройти». У «вершины» есть набор составляющих, который должен быть заполнен. Чтобы получилось событие, в предложении, кроме собственно глагола, обязательно должно быть указано название события и его дата. В случае глагола «пройти» название события должно быть подлежащим, в других контекстах оно может быть выражено другими синтаксическими ролями. Например, глагол «приглашать» требует, чтобы событие было выражено дополнением (приглашать на конференцию, приглашать в гости).

Кроме даты и названия, событие может содержать место и время. Организации и адреса выделяются грамматиками по внутренней структуре и по словарям. Например, если в названии есть ключевое слово «институт, банк, гостиница», то эти ключевые слова с зависимыми словами будут извлечены в качестве компании. В примере выше извлечется «Институт лингвистических исследований РАН».
Блок с информацией о событии показывается в интерфейсе Яндекс.Почты в момент открытия письма в заметной верхней части страницы. При такой компоновке время извлечения фактов критично — нельзя заметно увеличивать время ожидания пользователя. Нужно признаться, у нас не с первой попытки получилось добиться достаточной производительности. Объем собственных знаний парсера о русском языке вместе со словарями занимает около 1 Гб. Каждую секунду в Яндекс.Почте показывается около 1000 писем, и для каждого из них необходимо выделить факты и передать их во фронтенд для отображения. Несмотря на активное использование кеширования на стороне клиента, число запросов на извлечение оставалось слишком большим, чтобы успеть уложиться в оговоренное время.
Алгоритмы Томиты обрабатывают текст последовательно. Следовательно, чем больше сам документ, тем больше времени нужно для его обработки. Поэтому для того чтобы её ускорить, мы разбиваем текст на несколько частей и каждую из них обрабатываем отдельно в параллельном потоке. Причем, разбиваем текст по границам предложений — так снижается вероятность потерять важную информацию. Скорость ответов выросла, но вычислительных ресурсов существующего кластера было недостаточно, чтобы справиться таким потоком данных.
Конечно, можно было увеличить количество машин, занимающихся извлечением фактов, но мы решили поставить перед Томитой предварительный фильтр, который по специальному регулярному выражению определяет, может ли быть в документе событие или нет. В последнем случае текст не нужно отправлять на полное извлечение. Причем, мы намеренно подобрали такой regexp, который дает скорее больше ложноположительных срабатываний. Число запросов в парсер уменьшилось вдвое, а мы смогли разгрузить машины и освободить ресурсы для других задач.
События содержатся в 3,5% писем и каждый день мы извлекаем информацию более чем из миллиона событий. Сейчас в нашем корпусе примерно 500 шаблонов, на подходе ещё 3500, которые помогут нам радикально повысить точность работы.
Как парсятся электронные билеты
Через некоторое время после того, как были запущены извлечения событий, мы задумались о том, что можем помочь пользователям Яндекс.Почты и особенным образом показать информацию, которая есть в каждом электронном билете. Например, можно сообщать о пунктах назначения не заходя в письмо, дополнительно выделять электронный билет в списке писем, или, например, показывать погоду в городе прибытия.
Для билетов, состоящих из простого текста, мы использовали тот же парсер Томита, однако большинство писем от систем бронирования и авиакомпаний содержат html-разметку и почти не содержат естественный язык. Томита в таких условиях работает плохо, поэтому мы взяли за основу технологию, которая замечательно показала себя в Яндекс.Маркете. Мы используем html-разметку документа как xml-дерево тегов и строим шаблоны для разных отправителей. Перед разбором дерева мы дополнительно обрабатываем документ и приводим его к корректному с точки зрения xml виду.
По этим шаблонам, которые в основном состоят из регулярных выражений и xpath, мы выделяем необходимую информацию и формируем ответ. Не всегда удается выделить элемент дерева так, чтобы в нем содержалась только нужная часть информации, — примерно в трети случаев в элементе находится предложение с ключевой информацией. Так мы снова вспомнили про Томиту и создали набор грамматик для разбора таких предложений.
После извлечения базовой информации о билете из письма мы уточняем ее в Яндекс.Расписаниях, которые всегда содержат самую актуальную информацию о перелетах. На основе этой информации мы дополняем билет данными от других сервисов: погодой, курсами валют, ссылками на аэропорт и электронную регистрацию на рейс.

А что с приватностью?
Аудитория сайта Webtun.com как никакая другая знает, что в любой почте каждое письмо парсится десятками разных скриптов. Спамооборона так устроена — её работа сводится к автоматическому анализу писем и принятию решений о перемещении или не перемещении сообщения в спам.
Так же обстоят дела и с Томитой. Мы предусмотрели несколько уровней защиты, чтобы вы могли быть спокойны: текст анализируется только машиной — без какого-либо участия человека. В системных журналах сохраняется только статистическая информация о запросе: время выполнения, тип и количество найденных фактов, а также количество полей, которые удалось определить. Сам текст письма передается для извлечения фактов в обезличенной форме — без технических заголовков, без указания отправителя и получателя.
При первоначальном обучении системы и составлении грамматик без человеческого участия не обойтись — это кропотливый процесс, которым занимаются лингвисты. Для него мы используем тексты из открытых источников, например, комментарии в ЖЖ или социальных сетях. Если же примеров недостаточно, мы просим наших сотрудников прислать примеры подходящих писем для обучения и составления грамматик. Так мы поступили в случае с авиабилетами. Кроме того, мы составили топ-30 рассыльщиков авиабилетов и обучили Почту с ними работать. Посмотреть на то, как выглядят нововведения в Почте, можно здесь.

Комментировать статьи на сайте возможно только в течении 90 дней со дня публикации.